LonelyNathan
Run n8n with Ollama locally.
Your private AI automation workflow builder.
Download for Linux v0.0.0
Run n8n with Ollama locally.
Your private AI automation workflow builder.
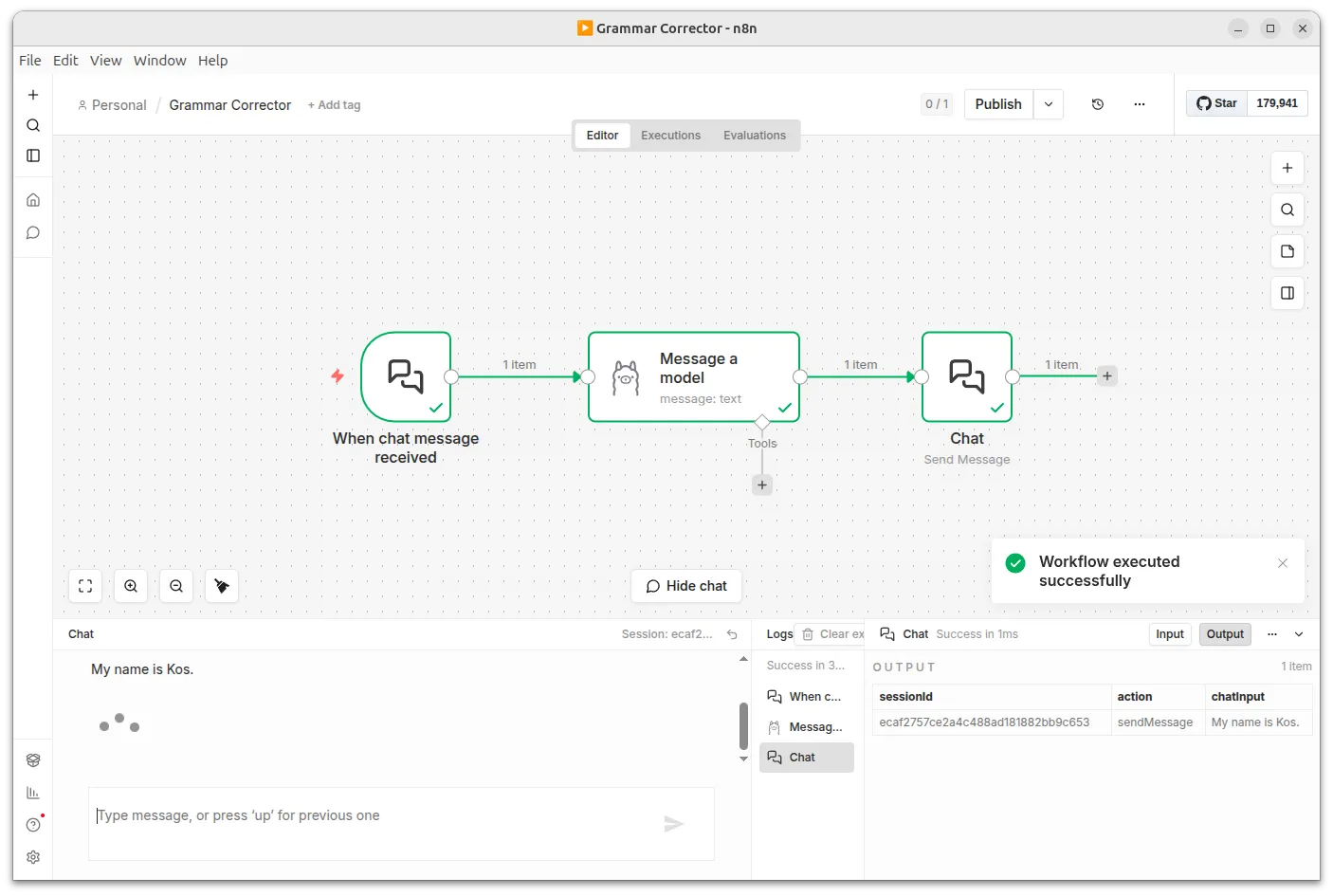
Everything you need to run AI-powered n8n workflows locally.
Run n8n and local AI models entirely on your machine, free of charge.
Your workflows and data never leave your computer.
No manual Docker commands, no config files to edit — just download and run.
Detects NVIDIA and AMD GPUs on first launch and lets you choose between GPU and CPU inference.
Ships with Ollama pre-configured, so AI-powered workflows work out of the box.
Pull any model from Ollama's library or connect to LM Studio, llama.cpp, or a host Ollama instance.
Runs the official n8n Docker image with no integrations removed or disabled.
n8n diagnostics and version notifications are disabled to match the local-first philosophy.
Local LLMs ready to power your workflows.